- Метод временных рядов
- Цель прогнозирующей модели
- Компоненты временного ряда
- Атрибуты набора данных
- Машинное обучение
- Понимание постановки задачи
- Метод построения Naive Approach
- Простой средний стиль
- Модель скользящей средней
- Экстраполяция шаблонов
- Метрики оценки и диагностика остатков
- Модель ARIMA
- Алгоритмы в SQL Server
На протяжении многих лет люди прогнозируют погодные условия, экономические и политические события и спортивные результаты, в последнее время этот обширный список пополнился криптовалютами. Для предсказаний разносторонних событий существует множество способов разработки прогнозов. Например, интуиция, экспертные мнения, использование прошлых результатов для сравнения с традиционной статистикой, а прогнозирование временных рядов — это лишь один из них, при этом самый современный и точный вид прогнозов с широкой областью применения.
Метод временных рядов
 Вам будет интересно:Ехидничать – это плеваться ядом в окружающих
Вам будет интересно:Ехидничать – это плеваться ядом в окружающих

Метод с использование временных рядов (TS) - это набор данных, который собирает информацию в течение определенного периода времени. Существуют специальные методы для выделения этого типа:
- линейные и нелинейные;
- параметрические и непараметрические;
- одномерные и многомерные.
Прогнозирование временных рядов приносит с собой уникальный набор возможностей для разрешения современных задач. Моделирование основывается на изучении, чтобы установить движущую силу изменения данных. Процесс происходит из долгосрочных тенденций, сезонных эффектов или нерегулярных колебаний, которые характерны для TS, и не наблюдаются в других типах анализа.
Машинное обучение является отраслью информатики, где алгоритмы составляются на основе данных и включают в себя искусственные нейронные сети, глубокое обучение, правила ассоциаций, дерева решений, обучения с подкреплением и байесовские сети. Разнообразие алгоритмов предоставляет варианты решения проблем, и каждый имеет свои требования и компромиссы к вводу данных, скорости работы и точности результатов. Они, наряду с точностью окончательных предсказаний, будут взвешены, когда пользователь решит, какой алгоритм будет работать лучше для изучаемой ситуации.
 Вам будет интересно:Инкорпорирующие языки: понятие, особенности, примеры
Вам будет интересно:Инкорпорирующие языки: понятие, особенности, примеры
Прогнозирование временных рядов заимствует из области статистики, но дает новые подходы для моделирования задач. Основная проблема для машинного обучения и временных рядов одна и та же - предсказывать новые результаты на основе ранее известных данных.
Цель прогнозирующей модели

TS представляет собой набор точек данных, собранных через постоянные промежутки времени. Они анализируются для определения долгосрочной тенденции, чтобы предсказать будущее или выполнить какой-либо другой вид анализа. Есть 2 вещи, которые отличают TS от обычной проблемы регрессии:
Цель модели прогнозирования временных рядов дать точный прогноз по запросу. Временной ряд имеет время (t) как независимую переменную и целевую зависимую переменную. В большинстве случаев прогноз — это конкретный результат, например, стоимость дома при продаже, спортивный итог соревнований, результаты торгов на бирже. Прогноз представляет медиану и среднее значение и включает в себя доверительный интервал, выражающий уровень доверенности в диапазоне 80-95 %. Когда они фиксируются через регулярные промежутки времени, то процессы называются временными рядами и выражаются двумя способами:
- одномерными с индексом времени, который создает неявный порядок;
- набор с двумя измерениями: временем с независимой переменной и другой зависимой переменной.
 Вам будет интересно:31 лицей Челябинска: лучшая физико-математическая подготовка
Вам будет интересно:31 лицей Челябинска: лучшая физико-математическая подготовка
Создание функций является одной из наиболее важных и трудоемких задач в прикладном машинном обучении. Однако при прогнозировании временных рядов не создаются функции, по крайней мере, в традиционном смысле. Это особенно верно, когда требуется спрогнозировать результат на несколько шагов вперед, а не только следующее значение.
Это не означает, что функции полностью запрещены. Просто их следует использовать с осторожностью по следующим причинам:
Однако нужно иметь в виду, что использование прогнозируемых значений в качестве признаков распространит ошибку на целевую переменную и приведет к ошибкам или даст смещенные прогнозы.
Компоненты временного ряда
Тенденция существует, когда ряд увеличивается, уменьшается или остается на постоянном уровне по времени, поэтому он принимается за функцию. Сезонность относится к свойству временного ряда, который отображает периодические шаблоны, повторяющиеся с постоянной частотой (m), например, m = 12 означает, что шаблон повторяется каждые двенадцать месяцев.
Фиктивные переменные аналогично сезонности могут быть добавлены в виде двоичной функции. Можно, например, учесть праздники, специальные события, маркетинговые кампании, независимо от того, является ли значение посторонним, или нет. Однако нужно помнить, что эти переменные должны иметь определенные шаблоны. При этом количество дней может быть легко рассчитано даже для будущих периодов и влиять на прогнозирование на основе временных рядов, особенно в финансовой области.
Циклы — это времена года, которые не происходят с фиксированной скоростью. Например, ежегодные атрибуты воспроизводства канадской рыси отражают сезонные и циклические модели. Они не повторяются через регулярные промежутки и могут возникать, даже если частота равна 1 (m = 1).
Lagged values - в качестве предикторов можно включить запаздывающие значения переменной. Некоторые модели, такие как ARIMA, векторная авторегрессия (VAR) или авторегрессионные нейронные сети (NNAR), работают именно таким образом.
Компоненты интересующей переменной очень важны для анализа временных рядов и прогнозирования, чтобы понять их поведение, шаблоны, а также иметь возможность выбрать подходящую модель.
Атрибуты набора данных

Возможно, программист привык вводить тысячи, миллионы и миллиарды точек данных в модели машинного обучения, но это не требуется для временных рядов. Фактически, можно работать с небольшими и средними TS, в зависимости от частоты и типа переменной, и это не является недостатком метода. Более того, на самом деле в этом подходе существует ряд преимуществ:
 Вам будет интересно:Стилистические функции антонимов: определение, типы и примеры
Вам будет интересно:Стилистические функции антонимов: определение, типы и примеры
Некоторые из этих наборов происходят из событий, записанных с помощью временной метки, системных журналов и финансовых данных. Поскольку TSDB изначально работает с временными рядами, это прекрасная возможность применить эту технику к крупномасштабным наборам данных.
Машинное обучение
Машинное обучение (МО) может превзойти традиционные методы прогнозирования временных рядов. Существует целый куча исследований, в которых методы машинного обучения сравниваются с более классическими статистическими для данных TS. Нейронные сети — это одна из технологий, которая достаточно широко исследована и применяет подходы TS. Методы машинного обучения лидируют в рейтинге по сбору данных на основе временных рядов. Эти подходы доказали свою эффективность, превосходя подходы с чистыми TS в соревнованиях с M3 или Kaggle.
МО имеет свои специфические проблемы. Разработка функций или создание новых предикторов из набора данных является важным шагом для него и может оказать огромное влияние на производительность и быть необходимым способом решения проблем тренда и сезонности данных TS. Кроме того, у некоторых моделей возникают проблемы с тем, насколько хорошо они соответствуют данным, и если нет, они могут пропустить основную тенденцию.
Временные ряды и подходы машинного обучения не должны существовать изолированно друг от друга. Они могут быть объединены вместе, чтобы дать преимущества каждого подхода. Методы прогнозирования и анализ временных рядов хорошо справляется с разложением данных на трендовые и сезонные элементы. Затем этот анализ можно использовать в качестве входных данных для модели МО, имеющей в своем алгоритме информацию о тенденциях и сезонности, что дает лучшее из двух возможностей.
Понимание постановки задачи
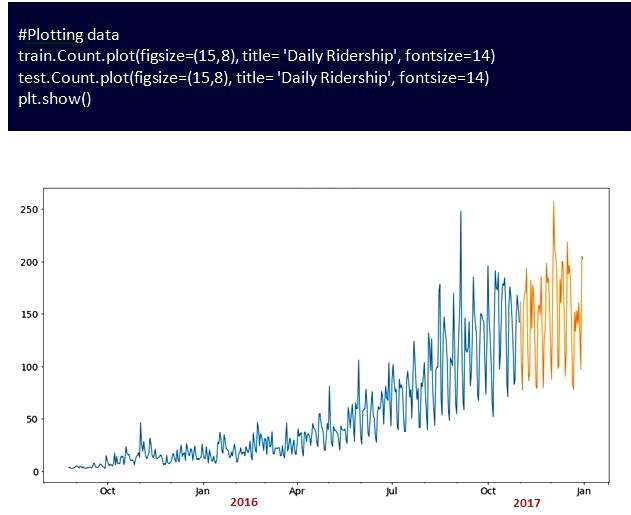
Для примера можно рассмотреть TS, связанный с прогнозированием количества пассажиров нового высокоскоростного железнодорожного сообщения. Например, имеются данные за 2 года (август 2016 г. - сентябрь 2018 г.), и с помощью этих данных нужно прогнозировать количество пассажиров на ближайшие 7 месяцев, имея данные за 2 года (2016–2018) на почасовом уровне с количеством путешествующих пассажиров, и необходимо оценить количество их в будущем.
Подмножество набора данных для прогнозирования с помощью временных рядов:

Выполняют визуализацию данных, чтобы знать, как они меняются в течение определенного периода времени.
Метод построения Naive Approach
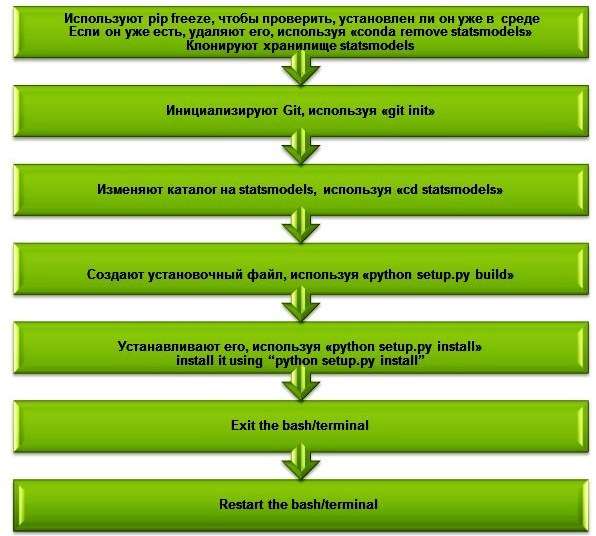
Библиотека, которую в данном случае использовали для прогнозирования TS, - statsmodels. Ее необходимо установить, прежде чем применять какой-либо из указанных подходов. Возможно, statsmodels уже установлена в среде Python, но она не поддерживает методы прогнозирования, поэтому потребуется клонировать ее из репозитория и установить с использованием исходного кода.
Для данного примера имеется ввиду, что цены на проезд монеты стабильны с самого начала и в течение всего периода времени. Такой метод предполагает, что следующая ожидаемая точка равна последней наблюдаемой точке и называется Naive Approach (Наивный метод).
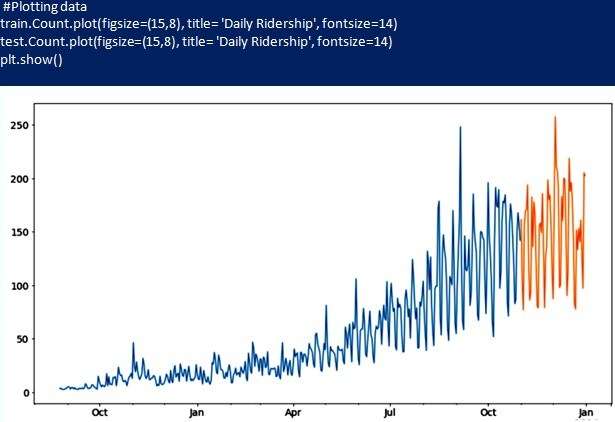
Теперь рассчитывают среднеквадратическое отклонение, чтобы проверить точность модели на наборе тестовых данных. Из значения RMSE и приведенного графика можно сделать вывод, что Naive не подходит для вариантов с высокой изменчивостью, а применяется для стабильных.
Простой средний стиль
Для демонстрации метода строится график, предполагая, что ось Y отображает цену, а ось X - время (дни).

Из него можно сделать вывод, что цена увеличивается и уменьшается случайным образом с небольшим запасом, так что, среднее значение остается постоянным. В таком случае можно прогнозировать цену следующего периода аналогичную средней за все прошедшие дни.
Такой метод прогнозирования с ожидаемым средним значением ранее наблюдаемых точек называется простым средним методом.
При этом берут ранее известные значения, вычисляют среднее и принимают его, как следующее значение. Конечно, это не будет точно, но довольно близко, и бывают ситуации, когда этот метод работает лучше всего.
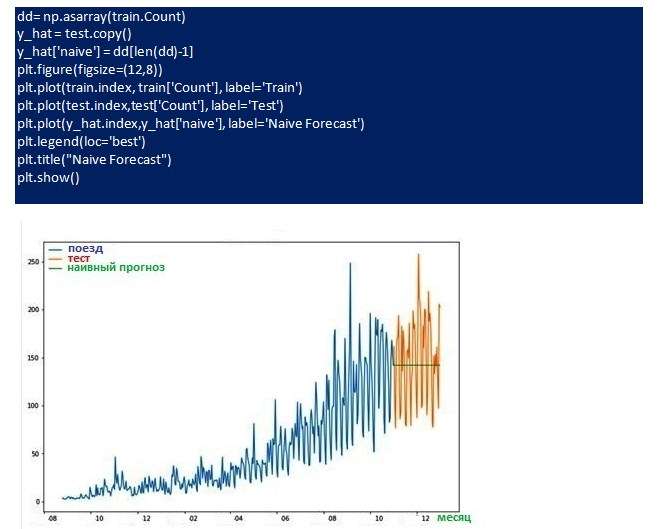
Исходя из результатов, отображенных на графике, видно, что этот метод работает лучше всего, когда среднее значение за каждый период времени остается постоянным. Хотя наивный метода лучше, чем средний, но не для всех наборов данных. Рекомендуется шаг за шагом опробовать каждую модель и посмотреть, улучшает ли она результат или нет.
Модель скользящей средней
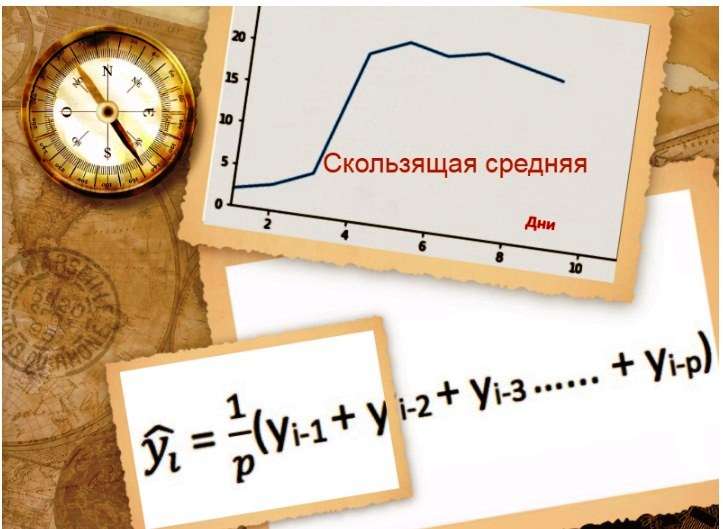
На основании этого графика можно сделать вывод, что цены несколько раз увеличивались прошлом с большим отрывом, но теперь стабильны. Для того чтобы использовать предыдущий метод усреднения, нужно взять среднее значение всех предшествующих данных. Цены начального периода сильно повлияют на прогноз следующего периода. Поэтому в качестве улучшения по сравнению с простым средним берут среднее значение цен только за последние несколько периодов времени.
Такая методика прогнозирования называется методикой скользящего среднего, что иногда называют «скользящим окном» размера "n". Используя простую модель, прогнозируют следующее значение в TS, чтобы проверить точность способа. Очевидно, что Naive превосходит как Average, так и Moving Average для этого набора данных.
Существует вариант прогноза методом простого экспоненциального сглаживания. В методе скользящего среднего, одинаково взвешивают прошлые «n» наблюдения. В этом случае можно столкнуться с ситуациями, когда каждое из прошлого 'n' влияет на прогноз по-своему. Такой вариант, который по-разному взвешивает прошлые наблюдения, называется методом взвешенного скользящего среднего.
Экстраполяция шаблонов
Одним из наиболее важных свойств, необходимых для рассмотрения алгоритмов прогнозирования временных рядов, является способность экстраполировать шаблоны за пределы области обучающих данных. Многие алгоритмы МО не имеют этой возможности, так как они имеют тенденцию ограничиваться областью, которая определяется данными обучения. Поэтому они не подходят для TS, цель которых — проецирование результата в будущее.
 Вам будет интересно:Антициклическая политика государства: понятие, виды, последствия
Вам будет интересно:Антициклическая политика государства: понятие, виды, последствия
Другим важным свойством алгоритма TS является возможность получения доверительных интервалов. Хотя это свойство по умолчанию для моделей TS, а большинство моделей МО не имеют этой возможности, поскольку не все они основаны на статистических распределениях.
Не стоить думать, что для прогнозирования TS используются только простые статистические методы. Это совсем не так. Есть много сложных подходов, которые могут быть очень полезны в особых случаях. Обобщенная авторегрессионная условная гетероскедастичность (GARCH), байесовские и VAR - лишь некоторые из них.
Существуют также модели нейронных сетей, которые можно применять к временным рядам, которые используют запаздывающие предикторы и могут обрабатывать такие функци как авторегрессия нейронных сетей (NNAR). Существуют даже модели временных рядов, заимствованные из сложного изучения, в частности, в семействе — рекуррентной нейронной сети, таких как сети LSTM и GRU.
Метрики оценки и диагностика остатков
Наиболее распространенными оценочными метриками для прогнозирования являются среднеквадратические средние значения, которые многие используют при решении проблем регрессии:
- MAPE, так как он не зависит от масштаба и представляет отношение ошибки к фактическим значениям в процентах;
- MASE, который показывает, насколько хорошо выполняется прогноз по сравнению с наивным средним прогнозом.
После того как метод прогнозирования был адаптирован, важно оценить, насколько хорошо он способен захватить модели. Хотя оценочные метрики помогают определить, насколько близкие значения равны фактическим, они не оценивают, соответствует ли модель TS. Остатки — хороший способ оценить это. Поскольку программист пытается применить шаблоны TS, он может ожидать, что ошибки будут вести себя, как «белый шум», поскольку они представляют то, что не может быть зафиксировано моделью.
"Белый шум" должен иметь следующие свойства:
Модель ARIMA
ARIMA - модель AutoRegressive Integrated Moving-Average, является одним из самых популярных методов, используемых в прогнозировании TS, в основном благодаря автокорреляции данных для создания высококачественных моделей.
При оценке коэффициентов ARIMA основное предположение состоит в том, что данные являются стационарными. Это означает, что тренд и сезонность не могут повлиять на дисперсию. Качество модели может быть оценено путем сравнения временного графика фактических значений с прогнозными значениями. Если обе кривые близки, то можно предположить, что модель подходит к анализируемому случаю. Она должна раскрывать любые тенденции и сезонность, если таковые имеются.
Затем анализ остатков должен показать, подходит ли модель: случайные остатки означают, что она точна. Подгонка ARIMA с параметрами (0,1,1) даст те же результаты, что и экспоненциальное сглаживание, а использование параметров (0,2,2) даст результаты двойного экспоненциального сглаживания.
Можно получить доступ к настройкам ARIMA в Excel:
Свод возможностей модели ARIMA:
Алгоритмы в SQL Server
Выполнение перекрестного предсказания является одной из важных особенностей временных рядов при прогнозировании финансовых задач. Если используются две взаимосвязанные серии, результирующая модель может применяться для прогнозирования результатов одной серии, основанной на поведении других.
SQL Server 2008 имеет новые мощные функции временных рядов, которые нужно изучить и использовать. Инструмент имеет легкодоступные данные TS, простой в использовании интерфейс для моделирования и воспроизведения функций алгоритма и окно объяснения со ссылкой на запросы DMX на стороне сервера, чтобы можно было понять, что происходит внутри.
Временные ряды рынка — это широкая область, к которой могут применяться модели и алгоритмы глубокого обучения. Банки, брокеры и фонды сегодня экспериментируют с их развертыванием анализа и прогнозирования индексов, курсов валют, фьючерсов, цен на криптовалюту, государственных акций и многого другого.
При прогнозировании временных рядов нейронная сеть находит предсказуемые паттерны, изучая структуры и тенденции рынков, и дает совет трейдерам. Эти сети также могут помочь в обнаружении аномалий, таких как неожиданные пики, падения, изменения тренда и сдвиги уровня. Многие модели искусственного интеллекта используются для финансовых прогнозов.