- Общее представление о системе
- Основные задачи
- Распределенная вычислительная среда
- Масштабирование базы данных
- Алгоритмы консенсуса базы данных
- Файловые системы хранения и тиражирования
- Система передачи сообщений
- Приложения по взаимодействию машин
- Примеры распределенных операционных систем
- Преимущества использования
Распределенная система в своем самом простом определении - это группа компьютеров, работающих вместе, что отображаются как один для конечного пользователя. Машины имеют общее состояние, работают одновременно и могут работать независимо, не влияя на время безотказной работы всей системы. Истина заключается в том, что управление такими системами - сложная тема, наполненная подводными камнями.
Общее представление о системе

 Вам будет интересно:Если речь косноязычная — это как?
Вам будет интересно:Если речь косноязычная — это как?
Распределенная система позволяет реализовать совместное использование ресурсов (включая программное обеспечение), подключенных к сети в одно и то же время.
Примеры распространения системы:
Распределенная система позволяет масштабироваться горизонтально и вертикально. Например, единственным способом обработки большего трафика будет обновление оборудования, на котором работает база данных. Это называется масштабированием по вертикали. Масштабирование по вертикали хорошо до определенного предела, после которого даже лучшее оборудование не справляется с обеспечением требуемого трафика.
Масштабирование по горизонтали означает добавление большего количества компьютеров, а не обновление аппаратного обеспечения на одном. Вертикальное масштабирование повышает производительность до новейших возможностей аппаратного обеспечения в распределенных системах. Эти возможности оказываются недостаточными для технологических компаний с умеренной и большой нагрузкой. Самое лучшее в горизонтальном масштабировании состоит в том, что нет ограничений на размер. Когда производительность ухудшается, просто добавляется другая машина, что, в принципе, возможно делать до бесконечности.
 Вам будет интересно:«Почаще»: слитно или раздельно? Как написание зависит от части речи?
Вам будет интересно:«Почаще»: слитно или раздельно? Как написание зависит от части речи?
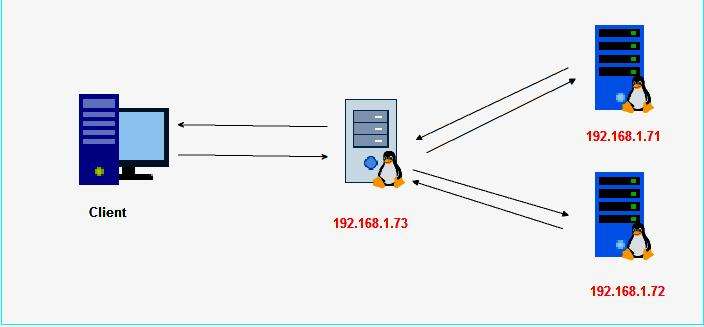
На корпоративном уровне распределенная система управления часто подразумевает выполнение различных шагов. В бизнес-процессах в наиболее эффективных местах сети компьютеров предприятия. Например, в типичном распределении с использованием трехуровневой модели распределенной системы обработки данных выполняется на ПК в месте нахождения пользователя, обработка бизнеса выполняется на удаленном компьютере, а доступ к базе данных и обработка данных осуществляется совершенно на другом компьютере, который обеспечивает централизованный доступ для многих бизнес-процессов. Как правило, этот вид распределенных вычислений использует модель взаимодействия "клиент-сервер".
Основные задачи
К основным задачам распределенной системы управления относятся:
 Вам будет интересно:Основные новообразования дошкольного возраста: общая характеристика развития ребенка
Вам будет интересно:Основные новообразования дошкольного возраста: общая характеристика развития ребенка
К задачам распредсистем относятся:
Распределенная вычислительная среда

(DCE) является широко используемым отраслевым стандартом, поддерживающим подобные распределенные вычисления. В Интернете сторонние поставщики предлагают некоторые обобщенные услуги, которые вписываются в эту модель.
Грид-вычисления - это вычислительная модель с распределенной архитектурой большого количества компьютеров, связанных с решением сложной задачи. В вычислительной модели сетки серверы или персональные компьютеры выполняют независимые задачи и слабо связаны между собой сетью Интернет или низкоскоростными сетями.
Крупнейшим проектом grid-вычислений является SETI@home, в котором отдельные владельцы компьютеров добровольно выполняют некоторые из своих циклов обработки многозадачности, используя свой компьютер для проекта поиска внеземного интеллекта (SETI). Эта компьютерная проблема использует тысячи компьютеров для загрузки и поиска данных радиотелескопа.
Одним из первых применений grid-вычислений было нарушение криптографического кода группой, которая теперь известна как distributed.net. Эта группа также описывает свою модель как распределенные вычисления.
Масштабирование базы данных

Распространение новой информации от ведущего к ведомому не происходит мгновенно. На самом деле существует временное окно, в котором можно получить устаревшую информацию. Если бы это было не так, производительность записи пострадала бы, так как пришлось бы синхронно ждать распространения данных распределенных систем. Они поставляются с несколькими компромиссами.
Используя подход подчиненной базы данных, можно горизонтально масштабировать трафик чтения в некоторой степени. Здесь много вариантов. Но просто нужно разделить трафик записи на несколько серверов, поскольку он не может его обрабатывать. Один из способов - использовать стратегию репликации с несколькими мастерами. Там вместо подчиненных есть несколько основных узлов, которые поддерживают чтение и запись.
 Вам будет интересно:Линейная скорость: формула нахождения
Вам будет интересно:Линейная скорость: формула нахождения
Другой метод называется sharding (разделение). С помощью него сервер разбивается на несколько меньших серверов, называемых осколками. Эти осколки имеют разные записи, создаются правила о том, какие записи попадают в какой осколок. Очень важно создать такое правило, чтобы данные распространялись равномерно. Возможным подходом к этому является определение диапазонов в соответствии с некоторой информацией о записи.
Этот осколочный ключ следует выбирать очень осторожно, так как нагрузка не всегда равна основам произвольных столбцов. Единственный осколок, который получает больше запросов, чем другие, называется горячей точкой, и стараются не допустить ее образования. После разделения данные перекалибровки становятся невероятно дорогими и могут привести к значительному простою.
Алгоритмы консенсуса базы данных

БД сложны для реализации в распределенных системах защиты, поскольку они требуют, чтобы каждый узел согласовывал правильное действие прерывания или фиксации. Это качество известно как консенсус, и он является фундаментальной проблемой в строительстве распредсистемы. Достижение типа соглашения, необходимого для проблемы «фиксации транзакции», является простым, если участвующие процессы и сеть полностью надежны. Тем не менее реальные системы подвержены ряду возможных сбоев процессов разбиения на сети, потерянные, искаженные или дублированные сообщения.
Это создает проблему, и невозможно гарантировать, что правильный консенсус будет достигнут в течение ограниченного периода времени в ненадежной сети. На практике существуют алгоритмы, которые довольно быстро достигают консенсуса в ненадежной сети. Кассандра фактически обеспечивает легкие транзакции посредством использования алгоритма Paxos для распределенного консенсуса.
Распределенные вычисления - это ключ к притоку обработки больших данных, который используется в последние годы. Это метод разбиения огромной задачи, например, совокупных 100 миллиардов записей, из которых ни один компьютер не способен практически ничего выполнять самостоятельно, на множество небольших задач, что могут вписываться в единую машину. Разработчик разбивает свою огромную задачу на многие более мелкие, выполняет их на многих машинах параллельно, собирает данные соответствующим образом, в таком случае будет решена первоначальная проблема.
Этот подход позволяет масштабировать по горизонтали - когда есть большая задача, просто добавляется больше узлов в расчет. Эти задачи на протяжении многих лет выполняет модель программирования MapReduce, связанная с реализацией для параллельной обработки и генерации больших данных наборов с использованием распределенного алгоритма на кластере.
В настоящее время MapReduce несколько устарела и приносит некоторые проблемы. Появились другие архитектуры, которые решают эти проблемы. А именно, Lambda Architecture для распределенной системы обработки потоков. Достижения в этой области принесли новые инструменты: Kafka Streams, Apache Spark, Apache Storm, Apache Samza.
Файловые системы хранения и тиражирования

Распределенные файловые системы можно рассматривать как распределенные хранилища данных. Это то же самое, что концепция - хранение и доступ к большому количеству данных по всему кластеру машин, являющихся единым целым. Обычно они идут рука об руку с Distributed Computing.
Например, Yahoo известна тем, что работает HDFS на более чем 42 000 узлов для хранения 600 петабайт данных, еще с 2011 года. "Википедия" определяет разницу в том, что распределенные файловые системы разрешают доступ к файлам с использованием тех же интерфейсов и семантики, что и локальные файлы, а не через пользовательский API, такой как язык запросов Cassandra (CQL).
Распределенная файловая система Hadoop (HDFS) - это система, используемая для вычислений через инфраструктуру Hadoop. Обладая широким распространением, он используется для хранения и тиражирования больших файлов (размер GB или TB) на многих машинах. Его архитектура состоит в основном из NameNodes и DataNodes.
NameNodes несет ответственность за сохранение метаданных о кластере, например, какой узел содержит блоки файлов. Они выступают в качестве координаторов сети, выясняя, где лучше хранить и копировать файлы, отслеживая состояние системы. DataNodes просто хранят файлы и выполняют команды, такие как репликация файла, новая запись и другие.
Неудивительно, что HDFS лучше всего использовать с Hadoop для вычислений, поскольку он обеспечивает информационную осведомленность о задачах. Затем заданные задания запускаются на узлах, хранящих данные. Это позволяет использовать местоположение данных - оптимизирует вычисления и уменьшает объем трафика по сети.
Межпланетная файловая система (IPFS) представляет собой захватывающий новый одноранговый протокол/сеть для распределенной файловой системы. Используя технологию Blockchain, она может похвастаться полностью децентрализованной архитектурой без единого владельца или точки отказа.
IPFS предлагает систему именования (аналогичную DNS), называемую IPNS, и позволяет пользователям легко получать информацию. Она хранит файл через историческое управление версиями, подобно тому, как делает Git. Это позволяет получить доступ ко всем предыдущим состояниям файла. Он все еще переживает тяжелое развитие (v0.4 на момент написания), но уже видел проекты, заинтересованные в его создании (FileCoin).
Система передачи сообщений

Системы обмена сообщениями обеспечивают центральное место для хранения и распространения сообщений внутри общей системы. Они позволяют отделить прикладную логику от непосредственного общения с другими системами.
Известный масштаб - кластер Kafka LinkedIn обрабатывал 1 триллион сообщений в день с пиками в 4,5 миллиона сообщений в секунду.
Проще говоря, платформа обмена сообщениями работает следующим образом:
Есть несколько популярных первоклассных платформ обмена сообщениями.
RabbitMQ - брокер сообщений, который позволяет более тонко настраивать управление их траекториями с помощью правил маршрутизации и других легко настраиваемых параметров. Можно назвать «умным» брокером, поскольку в нем много логики и плотно отслеживает сообщения, которые проходят через него. Предоставляет параметры для AP и CP из CAP.
 Вам будет интересно:Интересные факты о Средневековье: замки, рыцари, церковь, эпидемии
Вам будет интересно:Интересные факты о Средневековье: замки, рыцари, церковь, эпидемии
Kafka - брокер сообщений, который немного ниже по функциональности, так как в нем не отслеживается, какие сообщения были прочитаны, и не допускает сложной логики маршрутизации. Это помогает достичь удивительной производительности и представляет самую большую перспективу в этом пространстве с активной разработкой распределенных систем сообщества open-source и поддержкой команды Confluent. "Кафка" пользуется наибольшим успехом у высокотехнологичных компаний.
Приложения по взаимодействию машин
Эта распредсистема представляет собой группу компьютеров, работающих вместе, чтобы отображаться как отдельный компьютер для конечного пользователя. Эти машины имеют общее состояние, работают одновременно и могут работать независимо, не влияя на время безотказной работы всей системы.
Если считать базу данных как распределенную, только в том случае, если узлы взаимодействуют друг с другом для координации своих действий. Она является в этом случае чем-то вроде приложения, выполняющего его внутренний код в одноранговой сети, и классифицируется как распределенное приложение.
Примеры таких приложений:
Распределенные регистры можно рассматривать как неизменяемую, доступную только для приложений базу данных, которая реплицируется, синхронизируется и делится на всех узлах распредсети.
Известная шкала - сеть Ethereum - имела 4,3 миллиона транзакций в день 4 января 2018 года. Они используют шаблон Event Sourcing, позволяющий восстановить состояние базы за любое время.
Blockchain - это текущая базовая технология, используемая для распределенных регистров и фактически ознаменовавшая их начало. Это новейшее и самое большое новшество в распределенном пространстве позволило создать первый по-настоящему распределенный платежный протокол - биткойн.
Blockchain - это распределенная книга с упорядоченным списком всех транзакций, которые когда-либо происходили в его сети. Сделки группируются и сохраняются в блоках. Весь блок-цепочка по существу является связанным списком блоков. Указанные блоки дороги для создания и тесно связаны друг с другом посредством криптографии. Проще говоря, каждый блок содержит специальный хеш (который начинается с X количества нулей) содержимого текущего блока (в виде дерева Merkle) плюс хеш предыдущего блока. Для этого хеша требуется большая мощность процессора.
Примеры распределенных операционных систем
Типы систем появляются для пользователя, поскольку они являются однопользовательскими системами. Они делят свою память, диск и пользователь не испытывают затруднений при навигации по данным. Пользователь хранит что-то в своем ПК, и файл хранится в нескольких местах, то есть на присоединенных компьютерах, так что потерянные данные могут легко восстановиться.
Примеры распределенных операционных систем:
Если какой-либо компьютер загружается выше, то есть если многие запросы обмениваются между отдельными ПК, так происходит балансировка нагрузки. В этом случае запросы распространяются на соседний ПК. Если в сети становится больше нагрузки, тогда ее можно расширить, добавив в сеть больше систем. В сетевом файле и папках синхронизируются, и соглашения об именах используются таким образом, чтобы при извлечении данных не возникало ошибок.
Кэширование также используется при манипулировании данными. Для наименования файлов на всех компьютерах используется одно пространство имени. Но файловая система действует для каждого компьютера. Если в файле появляются обновления, то он записывается на один компьютер, и изменения передаются на все компьютеры, поэтому файл выглядит таким же.
В процессе чтения / записи происходит блокировка файлов, поэтому между разными компьютерами не происходит взаимоблокировки. Также происходят сеансы, такие как чтение, запись файлов за один сеанс и закрытие сеанса, а затем другой пользователь может сделать то же самое и так далее.
Преимущества использования
Операционная система разработана для облегчения повседневной жизни людей. Для пользовательских преимуществ и потребностей операционная система может быть однопользовательской или распределенной. В системе распределенных ресурсов многие компьютеры связаны друг с другом и совместно используют свои ресурсы.
Преимущества такой работы:
Это кратко о распредсистеме, почему ее используют. Некоторые важные вещи, которые нужно запомнить: они сложны и выбираются по соотношению масштаба и цены, и с ними труднее работать. Данные системы распределены в нескольких категориях хранилищ: вычислительные, файловые и системы обмена сообщениями, регистры, приложения. И все это только очень поверхностно о сложной информационной системе.